Uploading large files from iOS applications
The Bipsync Notes iOS app enables files to be stored and uploaded as a critical part of our users investment research. We recently improved the feature to accept files of any size, and we thought we’d share our approach.
Defining the problem
Previously, our upload feature restricted uploads to files with a maximum size of 20MB, which is a reasonable limit. Upon noticing 413 request entity too large errors in our logs – indicating that a client has tried to submit data that exceeds that amount – we decided to allow files of an arbitrary size.
Our existing upload code was aimed at users attaching small files such as PDFs to notes. These were uploaded as a single chunk of data using an NSURLSessionTask. We determined that this technique wasn’t suitable for larger files that we now support, like sketches or spreadsheets imported from Excel.
Crafting a solution
The typical solution in this scenario involves breaking the upload up into smaller chunks. Each chunk is uploaded separately before being reassembled on the server to reform the original file.
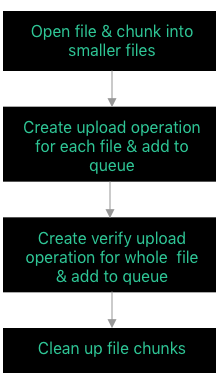
Let’s discuss each of those steps.
Step 1: Open file and chunk into smaller files
The first step is to split the file into smaller chunks if the file size is larger than our chunk size, which in our case is 512kb.
Our first attempt at this involved loading the file into an NSData object using its dataWithContentsOfURL method, splitting that object into multiple objects containing smaller chunks, then writing each object’s data to a file.
Why write to file at all? Wouldn’t it be easier to just upload each chunk as NSData?
Yes, much easier! However we use a background session for our upload/download operations so the app continues these activities when backgrounded. Since background sessions can only work with files and not NSData objects because they’re not persistent, we’re forced to write all upload data to disk.
However Apple’s documentation actually recommends using an NSInputStream instead of NSData; this allows us to load chunks of the file individually, without first loading the whole file into memory and keeping it there.
“Use this method to convert data://URLs to NSData objects. You can also use it to read short files synchronously. If you need to read potentially large files, use inputStreamWithURL: to open a stream, then read the file incrementally.”[1]
To keep our app memory efficient and reduce the risk of it being killed by iOS’ watchdog for using too much memory, we decided to take Apple’s advice.
Using an NSInputStream adds more complexity to the read-in operation because managing the data stream in chunks involves providing an NSStreamDelegate instead of just accessing an NSData object.
To do this we create an NSOperation queue with its maxConcurrentOperationCount set to one, and wrap each read of the stream into memory and its subsequent write in an NSBlockOperation. This helps use keep the memory footprint down as we only access one chunk at a time.
We found a great tutorial on how to do this efficiently here [2].
Here’s how the code for that looks:

Step 2: Create upload operation for each file and add to queue
We’ve previously written about our use of NSOperation, based loosely on this WWDC talk from 2015 [3]. We use them extensively to make our code easier to reason about, usually when we’re working with a graph of sequential dependencies.
In this step we create an NSOperation for each file chunk and POST the data to our API. To do this we pass the URL of each file chunk to our custom NSOperation and add it to a NSOperationQueue.
We again set our queue’s maxConcurrentOperationCount property to one so that if any of our uploads fail, we cancel the whole operation. This prevents any files from being partially uploaded. In future we can improve this to allow failed uploads to be restarted from the last successfully uploaded chunk.

Step 3 – Create verify upload operation for whole file & add to queue
The final step involves using our API to validate that the upload has been successful. To do this we have an endpoint that we send the total file chunks we expect to be uploaded and the API returns whether it has recieved these or not.
If the upload has succeeded and all chunks are accounted for we save the file with its remoteFileID property which is returned from the API. We use this value on the device to effectively denote whether it has been successfully uploaded or not.
Step 4 – Clean up file chunks
The final step in the process is to clean up the file chunks we created. We do this whether or not the upload succeeded, to ensure that we don’t keep any redundant files on the device.
Memory management
Any iOS app needs to be mindful of memory management. We need to be careful we don’t keep file chunks around on the device, especially from large files, because they take up storage space. More importantly though, we need to keep our memory footprint low so we don’t affect the performance of both our app, and other apps running on the device. iOS 13 seems to be particularly harsh with memory management, often killing apps that are memory-heavy.
To ensure we aren’t using more memory than we need and to keep our app responsive we can use Apple’s memory debugger developer tool to ensure we aren’t using too many resources.

To test this we used an iPad Pro and a 200MB file. The app initially uses 38MB of memory after loading. Upon importing the file using our Share Extension we can see a large memory spike to 238MB as the file is copied to the app.
The initial spike is caused by the NSStreamEventHasBytesAvailable event on NSInputStream which has to read the whole file in order to know how many bytes it has. The app then settles to around 43MB while the app is uploading and back down to 42MB once the upload is complete.
If we compare this to loading the data in as NSData and keeping the chunks in memory – illustrated below – chunking via an NSInputStream is clearly more memory efficient.

Our new Files improvement, which allows files to be stored and uploaded in the app without being associated with Notes, is available now. The changes to uploading described above will be available from the App Store very shortly.
[1] https://developer.apple.com/documentation/foundation/nsdata/1547245-datawithcontentsofurl?language=objc
[2] https://www.objc.io/issues/2-concurrency/common-background-practices/
[3] https://developer.apple.com/videos/play/wwdc2015/226/