2024 Bipsync RMS Technology Overview
People are often curious as to how Bipsync works. It’s easy to assume from a few screenshots that our research management software (RMS) is a straightforward web app, but looks can be deceiving — there’s a lot going on under the hood. Bipsync is essentially a platform comprised of several applications that work together to power the functionality that our users require. In this post, we’ll delve into our technology stack and explain how it all fits together.
Applications and APIs
Bipsync is essentially a suite of applications, APIs, and tools that make up our RMS platform. The broad aim of the platform is to facilitate the ingestion of data from any feasible location (e.g. user input, email, third party APIs, etc.), store it securely, and allow it to be consumed, analyzed, collaborated on, and exported in a myriad of ways. This requirement has led to us developing several distinct applications which serve its own dedicated purposes. These apps are served by our Data API which interfaces with the databases and services that power the platform — such as MongoDB, Elasticsearch, RDS, and so on.
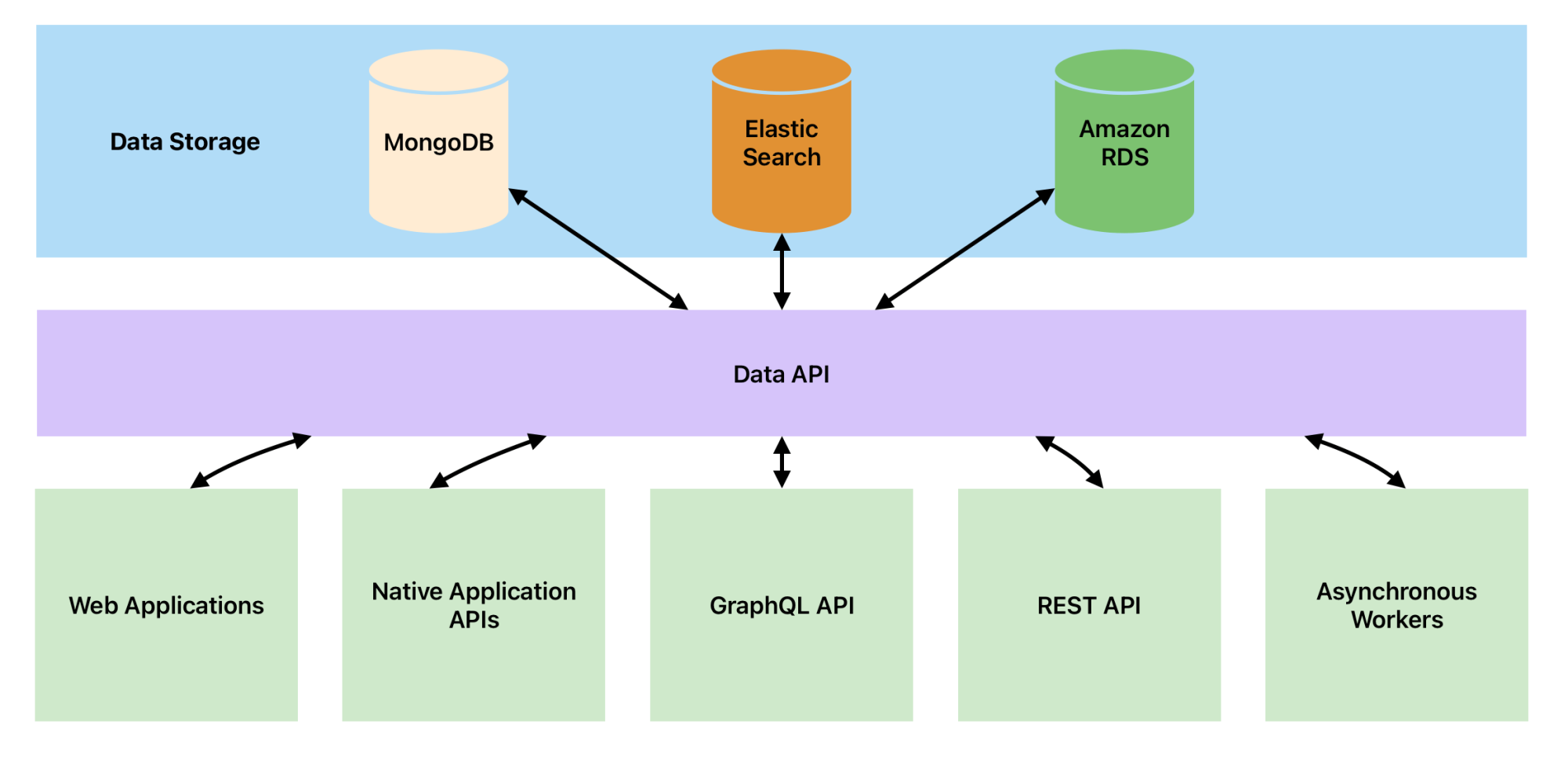
Let’s walk through each of these sections.
Data Storage
Bipsync uses several different data storage solutions, selecting the most suitable tool for the job based on our specific objectives.
Our primary data store is hosted in MongoDB. This article goes into the reasons why MongoDB is a crucial part of our stack, but in short, its dynamic schema underpins a key feature offered by Bipsync: a flexible data model which can be adapted to suit each client individually.
We use Elasticsearch for anything that needs to be found by full text queries or more complex search strategies. For some queries, like counts, Elasticsearch performs much better than MongoDB.
Amazon Relational Database Service (RDS) is an AWS service which hosts several different database vendor solutions in a very scalable fashion. We host our reporting databases here because MySQL, as a relational database, is a better fit than MongoDB for the types of queries that are run in reporting scenarios.
The Data API
No application queries our data stores directly. Instead they communicate with the “Data API” which, in turn, talks to our stores. This is a microservice-style approach which allows us to localize our database queries and re-use them among all of our applications.
We’ve written about this in more detail here, but essentially the main advantage of this approach is that our point of integration for data access and control isn’t the database, but an API – so we don’t need to fuss with stored procedures or foreign key constraints at the database level, and instead enforce them through code. We’ve found this to be a much simpler way to work.
While we tend to use PHP, as it’s familiar to most of us, this design makes it trivial to write applications in any language that is able to communicate over HTTP – a Ruby app or a Python app or a Go app could message the Data API just the same. Our applications are less complex as a result of not needing to worry about database access. We’ve found that we’re able to lean on smart APIs that are designed specifically for, and can grow with, their clients.
Web Applications
We have several web apps, each focussing on a different use case of the RMS: research consumption, compliance reporting, configuration, and so on. Each application solves a problem in the most appropriate way, and similarly, we’ve chosen an appropriate tech stack to go with it.
Most use PHP on the back-end. We use the Slim framework as a basic architecture and complement that with some Symfony components, but the majority of our PHP code is domain-specific and is mostly concerned with manipulating data as it flows between a data store and a client. We use the latest version of PHP and strive to keep it up to date as new versions become available (as indeed we do with all of the technology we use) – thanks to our dedicated Platform and Infrastructure teams.
Web applications that have a user interface will usually employ some degree of JavaScript on the client. We use a few notable frameworks such as Vue, React, and Backbone. We’ve incorporated Web Components to make our code modular in a framework-agnostic manner, and have embraced ECMAScript 6 to write modern front-end code.
A word on frameworks: As a rule of thumb, we try to avoid ending up in a position where removing, replacing, or upgrading a framework or library will necessitate months of work. That way risk is minimized, we all have a good understanding of how the system works, and we only tend to implement features we absolutely need (since we don’t have time to write extraneous code, as is tempting when someone else has done much of the work for you). Generally, we try to keep our dependencies to a minimum.
Native Applications and their APIs
Through our web apps, our users can manage their research, contacts, tasks, and much more. However, due to their nature, there’s a limit to what a web app can do – they are restricted from accessing the filesystem, for example. Our users are often travelling, sometimes on planes with no connectivity, and therefore require a way to access their research that isn’t dependent on an internet connection. They also have a lot of content in other applications such as models in Microsoft Excel, and want that content to be managed by and accessible from Bipsync too. They also want to take advantage of all the features a modern smartphone, tablet, or computer can offer. Part of Bipsync’s magic is that it’s available pretty much anywhere our users may be working.
Bipsync Notes iOS
Our iOS app is written in Swift with a smattering of Objective-C left around from the early days. Crafting apps for iOS is a notoriously more intensive process than that of making apps for the web. Mobile devices have less resources to rely on, the severe nature of crashes mean errors have to be avoided like the plague, and there are some genuinely tricky concepts like threading to understand if the app is to be as responsive as our users expect.
We’ve found working on the app to be a challenging, but very rewarding, experience. It’s tailored toward doing one thing really well, which is simply to allow users to access their research at any time, anywhere they are.
The app uses Core Data to model and store data, and communicates with its web API through a set of sync operations that run in background threads to keep the app’s interface smooth. Our focus has been on ensuring that research content is always up to date and easily accessible; implementing background fetch and a proprietary full-text search solution were key milestones.

We’ve also dedicated a lot of time to our custom-built rich text editor which mirrors its counterpart in the web RMS in terms of functionality and behavior. It uses Apple’s WebKit modules to send messages between processes written in both Objective-C and JavaScript.
Other cool features in the app include an AI/ML-powered business card scanner; feature-rich PDF viewer and annotator; support for biometric authentication; a Safari extension which allows web pages to be clipped to Bipsync; a OCR scanner to extract text from images; and even a couple of Easter eggs such as a Messages sticker pack, which we released as a Christmas gift.
The iOS app is also fully compatible with enterprise MDM solutions such as InTune, Airwatch, and MobileIron.
Bipsync Notes Desktop
On Windows and MacOS we offer a desktop app. As with the iOS app, one of the main advantages of a native program is the ability to work offline with confidence with no loss in functionality. The app also boasts a fast full-text search.
We use Github’s Electron framework which lets us use the same languages – HTML, JavaScript and CSS – as we use in the web app. Our familiarity with these technologies means we were able to get a compelling product together relatively quickly. We’re also able to lean on Node.js and the libraries in NPM to offer cool features that are only possible with a native app, like integration with the OS’ taskbar/dock, file watching and syncing, and supporting multiple windows.
Like our iOS app, the desktop app has been designed to quickly synchronize with the RMS’ data store through its own custom web API. Where the mobile API has to tailor its responses to accommodate for cellular data speeds and restrictions, the desktop API can rely on faster, more stable connections so we’re able to get data up and down much more quickly. We encrypt all data, both in transit and at rest; the app uses a MongoDB compatible database to store data on the machine.
The desktop app uses the same rich-text editor as the web RMS app: CKEditor. It’s a great library that’s easy to customize through plugins, which we can re-use across both the web and native apps. Backbone.js is another library which is used on both web and desktop platforms – we love it for the way it empowers event-driven applications to easily respond to changing data without being too prescriptive in how those applications should be structured.
As with all our apps the desktop app is backed by a suite of automated tests to ensure the app runs successfully – and almost identically – on both Windows and OS X platforms. It’s a genuinely impressive thing to see in action.
Plugins, plugins, plugins
I mentioned earlier that our users often want to integrate Bipsync into existing workflows which involve third-party applications, such as those in the Microsoft Office suite (Excel, Outlook, etc.). Perhaps they’d like to be able to forward research-related emails in to Bipsync and have them stored as notes, or work on a model in Excel and have that file automatically upload itself to a related note in Bipsync.
We recently introduced another Windows app, written in .NET and including add-ins for Office and Acrobat, which allows users to easily import files into our system. To achieve this, we have a few plugins that appear as buttons in their respective apps. The behavior varies depending on the app, but in Outlook for example (there’s a nice image of this below) tapping the button will send the email in to Bipsync, and even allows tags to be added from within Outlook itself.

Our Excel plugin works in a similar fashion, but here we go one step further and track the file that was sent to us. Email is immutable, but Excel files are not – so as further changes are made to the file and it is saved, we automatically sync the updated version of the file to Bipsync. We’re even able to extract values from cells in a spreadsheet and map them to various data properties within Bipsync.
The way these plugins are architected is pretty neat. They’re bundled with the desktop app installer, and then for all non-specific functionality – e.g. uploading a file to Bipsync – they pass the work off to the desktop app. This reduces the complexity of each plugin, instead locating that logic in a single place.
We also have a Chrome browser extension which clips web pages of interest in to Bipsync, an Excel extension which can import data from a spreadsheet, and numerous other little tools and helpers written in several different languages.
All of these apps communicate with Bipsync via dedicated APIs, though we are increasingly bringing the GraphQL API into play to unify the logic involved. On that note…
GraphQL and REST APIs
Bipsync’s API is its secret weapon. We use it ourselves to perform data migrations, backups, and ad-hoc integrations with third-party products, but it’s also used heavily by our clients. Our flexible data model means that clients can bring their own data, such as security masters or investment portfolios, and we can shape how that data is represented in the system.
Our original API is a REST-like affair, aimed at managing individual items of content at a time. That works well for certain simple use cases, but as time went on we noticed that some tasks it was employed for, like custom reports, weren’t able to run as efficiently as we’d like. This was particularly apparent when trying to work with referential data because the REST API wasn’t designed to prioritise relationship traversal. This is where GraphQL shines — it’s able to not only fetch just the properties of one resource but also smoothly follow references between them, all in a single request. This can have a transformative effect on certain use cases.
We use Swagger to generate API documentation in OpenAPI format. If you’re interested in that, check out our documentation portal.
Asynchronous Workers
Any potentially computationally-expensive or long-running work is processed asynchronously in one of two ways: locally or remotely.
Tasks which need to be processed locally are handled by our own queueing solution which employs Supervisor, a tool that runs as a daemon and manages other processes. These processes are command line operations that are executed on demand, which could mean anything from a simple unix program to a bash script or a complicated command-line application. Most of the time, they’re PHP scripts which interact with our Data API. Some are substantial enough that they could be considered applications in their own right. There’s one to import emails from a given mailbox and convert them to notes in our system, one to import a user’s entire Evernote account in to Bipsync, and one to export a fund’s entire research portfolio to Bloomberg so it can be integrated into their Bloomberg Terminal.
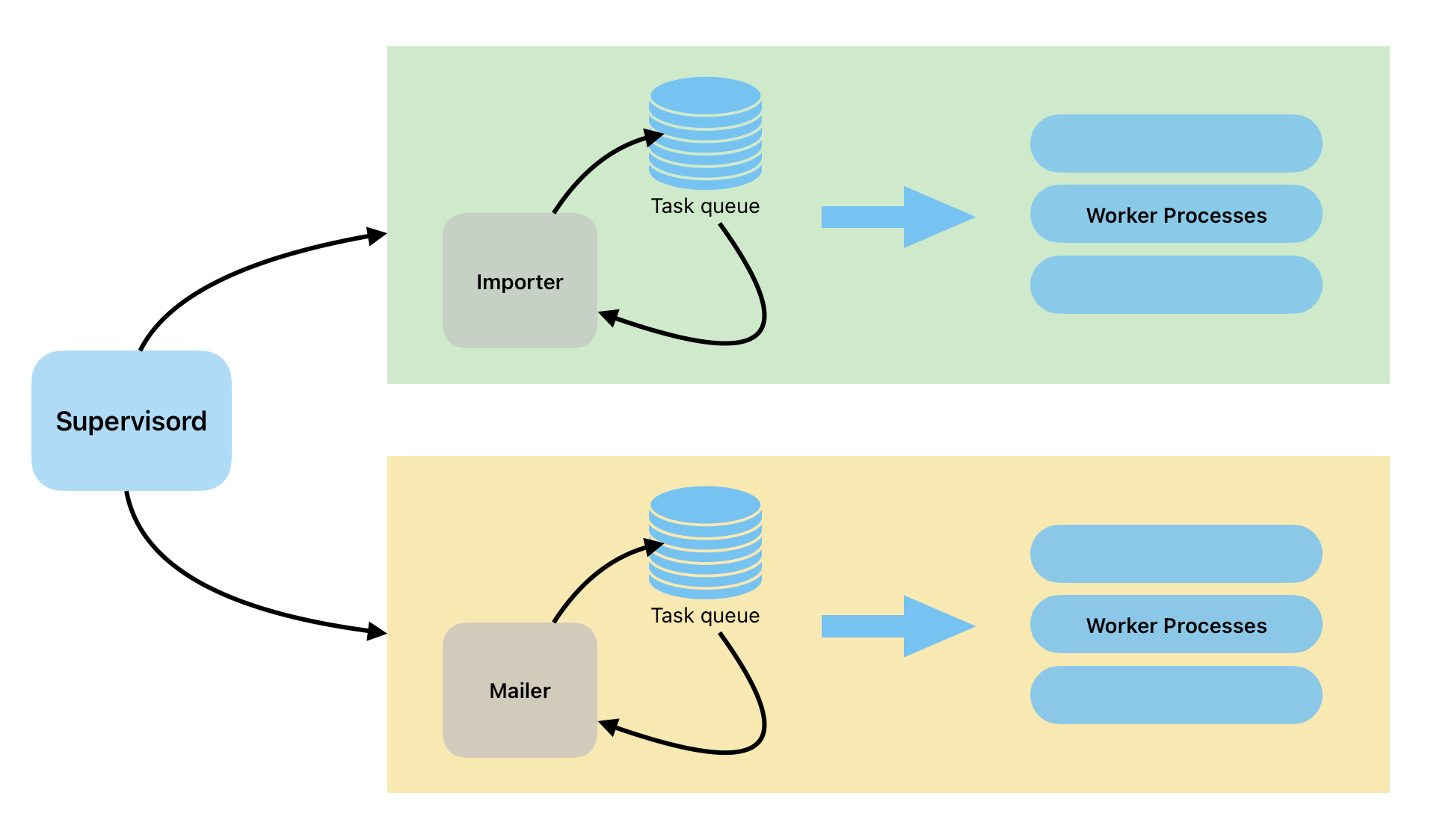
Our web applications place these locally-executed tasks into a collection in MongoDB which acts as a queue. From here they’re popped off and processed by the task daemons in a timely fashion. Supervisor is responsible for managing many of our more complex integrations, such as our integration with Microsoft Exchange. We can tailor the workers to run at appropriate intervals, ensuring that data is synchronized as often as our users expect. We also run our custom scripting system in this way, which allows our clients to craft their own integrations which can export or import data on demand or on a schedule.
Where a task doesn’t need access to Bipsync resources like our data stores, we instead process them remotely in AWS in a centralised fashion. Each task will be implemented differently depending on what it’s doing, but typically we’ll use AWS SAM to compose a solution that uses AWS resources like SQS, Lambda, and API Gateway. We still track the work in our system, but it’s executed in AWS. This reduces load on our instances, and allows us to scale indefinitely, which is useful when you consider that we often need to queue hundreds of thousands of tasks.
Generally, anything that might take the system a non-trivial amount of time to process gets implemented as a task. This keeps our web processes nice and quick, our web servers idle, and our users happy – because the app is incredibly responsive as a result.
That’s it! For now…
It’s nice to stop and take stock of things every once in a while. I can scarcely believe how much our platform has grown, and looking at our roadmap I imagine the same will be true a year from now. Hopefully this has given you some insight into what we software developers do at Bipsync, and if you’re thinking “wow, that’s a lot of work for a small team”: well, we’re hiring!
Take a look through our current job vacancies here, then get in touch and help us out!